
Magazine: Features
Analyzing the Amazon Mechanical Turk marketplace
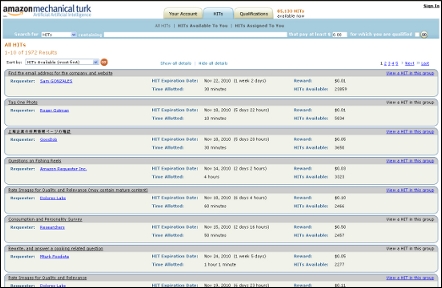
An associate professor at New York Universitys Stern School of Business uncovers answers about who are the employers in paid crowdsourcing, what tasks they post, and how much they pay.
Analyzing the Amazon Mechanical Turk marketplace
Full text also available in the ACM Digital Library as PDF | HTML | Digital Edition
Thank you for your interest in this article. This content is protected. You may log in with your ACM account or subscribe to access the full text.
Pointers
Jargon
Complete Automated Public Turing test to tell Computers and Humans Apart: A contrived acronym intentionally redolent of the word “capture,” used to describe a test issued on web forms to protect against automated responses.
Game with A Purpose: a term used to describe a computer game that layers a recreational challenge on top of a problem that demands human intelligence for efficient solution, e.g.: protein folding.
Human Intelligence Task: A task that an AMT requester is willing to pay to have accomplished by AMT providers. More generally, a task that may be best completed via crowdsourcing.
Human-Guided Search: A research project investigating a strategy for search and optimization problems that incorporates human intuition and insight.